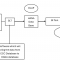
I am currently doing a course on getting and cleaning data. R programming language is the tool I use to clean data. I decided to look at the SAP SuccessFactors Add-On downloads data just for fun. These are the steps involved. You could do the same with Excel, But R lets you handle large volumes of data and perform actions that are not very easily possible with Excel. This is a simple exercise. But it demonstrates the logical process any data scientist or analyst would follow.
The Question for which I need an answer
The most important thing in data analysis is the question you want answered. In my case, I want to see which countries have the most interest in the SAP SuccessFactors Add-On. I suspect US and Germany will be at the top. But I have no idea which other countries show the most interest. Let us find out.
These are the steps and the R code to perform functions
Step 1: Read the data file which is available to me as a CSV file.
downloads <- read.csv(“downloads.csv”)
This reads the raw data I got from the data base into a data frame called downloads.
Step 2: Select just the data I need.
The new dataframe downloads will have multiple rows with the same country names. I want to find out how many times each country name is listed. I can use the table function to find that out.
countrycount <- as.data.frame(table(downloads$Country.Name))
The above code creates a dataframe with the name of countries in one column and the number of times they occur in the original table in a second column names Freq,
Step 3: I then want to sort the data with the country with the most downloads on the top.
This is the R code to do that.
sort(countrycount$Freq, decreasing = TRUE)
Step 4 : The last step is to write the data to a CSV file so that I can share the data with other people and systems. This is the code for that.
write.csv(countrycount, “countrycount.csv”)
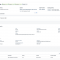
Now let us look at the data.
Customers from the US downloaded the Add-On the most. No surprise there. We have thousands of SAP ERP HCM customers in the US. The second is Germany. No surprise there either. Third is Australia. Fourth is Saudi Arabia. That is good to know. There is a lot of interest in Australia and Saudi Arabia. There is a lot of interest from many European customers for the Talent Hybrid model. This information gives me and my product management colleagues enough insight to make some data driven decisions. Of course I have a lot more data than this and can find answers to many more such questions.
The next step could be to visualize this data to convey the information quickly. Many tools including R can do that. I will get to it in the future.
United States -> 3056
Germany -> 1046
Australia -> 867
Saudi Arabia -> 747
India -> 674
United Kingdom -> 519
Canada -> 474
Switzerland -> 434
Denmark -> 413
Brazil -> 393
Belgium -> 374
Spain -> 300
Chile -> 239
Netherlands -> 212
Mexico -> 168
China -> 139
Peru -> 132
South Africa -> 132
Hong Kong -> 114
Turkey -> 113
Austria -> 99
Argentina -> 93
Finland -> 92
Norway -> 86
Russian Feder. -> 70
Singapore -> 70
France -> 68
Colombia -> 63
Italy -> 58
South Korea -> 55
Dominican Rep. -> 37
Sweden -> 35
United Arab Em. -> 32
Qatar -> 31
Cyprus -> 28
Andorra -> 24
Ireland -> 24
Egypt -> 23
Poland -> 23
Liechtenstein -> 22
Nigeria -> 22
Portugal -> 21
Panama -> 18
Japan -> 16
Venezuela -> 16
Bangladesh -> 14
Israel -> 14
Vietnam -> 14
Zimbabwe -> 14
Trinidad,Tobago -> 13
Cambodia -> 12
Hungary -> 12
Iceland -> 12
Thailand -> 11
Jamaica -> 10
New Zealand -> 10
Czech Republic -> 9
Malaysia -> 8
Canary Islands -> 6
Ecuador -> 5
Kazakhstan -> 5
Indonesia -> 4
Philippines -> 4
Luxembourg -> 2
New Caledonia -> 1
Slovenia -> 1