This Blog post explains how to automate/integrate HANA snapshot with google cloud storage snapshot.
Due to volume data , HANA database size is keep on increasing and traditional online backups i.e. full , differential , incremental takes longer time. Longer running backups use heavy disk io and it impacts HANA operations i.e thread locking , longer savepoints , longer commit time etc. which finally impacts application processing time i.e. Jobs , dialog users response time etc.
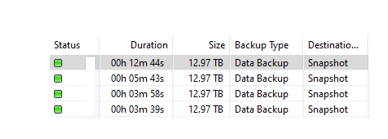
As you see below screen. Overall HANA snapshot process can be finish in minutes compare to 4/5+ hours – depend on DB size. Snapshot backup runtime is depend on snapshot runtime so irrespective of database size like traditional backups.
HANA snapshot history from catalog
Lets dig more on details.
Short story on how HANA snapshot was useful on reducing overall migration project outage window.
We were working on DB2 –> HANA DMO based migration project. HANA environment was with primary –> secondary and DR databases. database size in HANA was around 5TB. we wanted to release environment for business users only after replication sync across all servers i.e. with HA / DR capability.
But after migration HANA do not allow replication without full backup and backup was taking around 5 hours (1TB per hour throughput). replication after 5 hours of backup was delaying overall migration outage window.
Implemented HANA snapshot this time which completed in around 10 minutes. later replication started across secondary and DR along with parallel application post-processing activities
It allowed us to execute multiple tasks in parallel and reduced overall migration outage window.
Safer side we also took vm snapshot ( all disks) as offline backup of server/HANA database.
5 Step HANA snapshot process

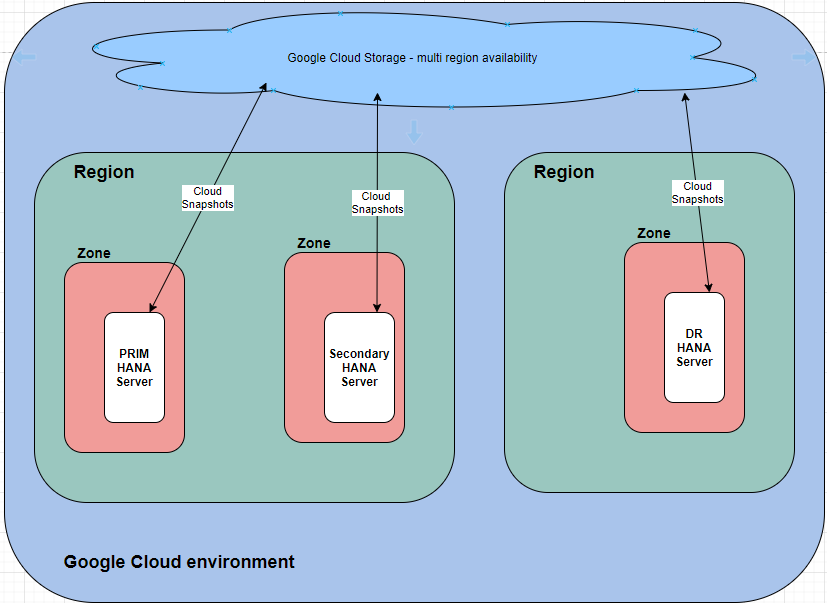
Cloud storage snapshots – high level setup.
- Once created cloud snapshots available across region for recovery i.e for DR recovery / until retention time.
- Technically such recovery require only after – if HANA replication fails OR HANA database is not coming up due to some hardware / software issues.
- HANA snapshot triggers only from Primary. but it also available from other servers in case of falled-over situation.
High level prepared diagram to understand HANA environment in cloud.
Cloud snapshots – 2 methods
1st method –> Trigger cloud storage snapshot directly from script after HANA prepare step. Remember, manually created snapshot require manual deletion. so cloud snapshot retention require some additional steps for manual cleanup.
- Start PREPARE HANA step and capture respective backup id from HANA catalog.
- Freeze /hana/data disk.
- Trigger cloud snapshot command from script – using google cloud service account.
- Un-freeze /hana/data disk.
- Close HANA Snapshot.
- 2nd method would be to align cloud snapshot schedule with Script i.e. cloud snapshot retention can be configure at console level – No manual efforts for cleanup.
- Start Prepare HANA step and capture respective backup id from HANA catalog – 9.55am
- Freeze /hana/data disk
- Pause script for 15 minutes and schedule cloud snapshot from console to start/end during this time i.e. 10am
- Un-freeze /hana/data disk
- Close HANA Snapshot
Preparation
- Understand HANA disk details on server
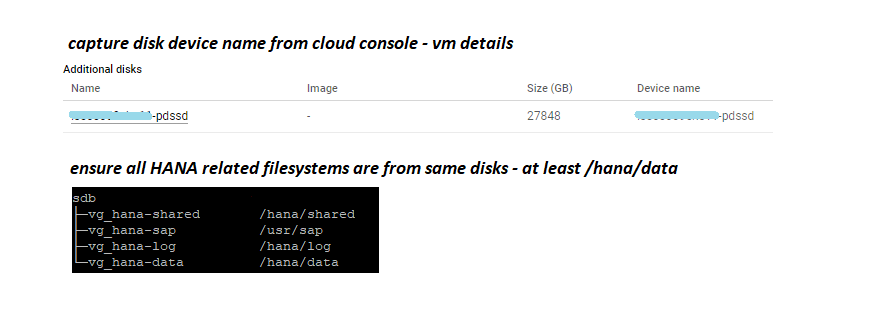
- HANA user account has HANA snapshot respective authorization.
- Ensure default storage snapshots i.e hourly are disabled on disk. its cost saving option. as best practice better to have daily once all disk snapshots.
- Google service account from HANA server (os level ) has access to create / delete cloud snapshots – if using 1st method from above.
- HANA userstore key created for systemdb login to use in script – password encrypted – Port 3XX013
Note –> HANA snapshot doesn’t check block level corruption like traditional backups. kindly refer SAP documentation around this topic.
Method 1 – Automate HANA Snapshot using google command triggered snapshots.
## Kindly add necessary error handler as best practice
# iPrefix value from command line parameter
# SYSDBKEY value from command line parameter
DATE_TIME="`date \"+%Y%m%d_%H_%M_%S\"`"
iPrefix="$DATE_TIME"_"$iPrefix"
#
msnapshotsql="BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT '$iPrefix'"
mcatid="SELECT MAX(ENTRY_ID) FROM M_BACKUP_CATALOG WHERE ENTRY_TYPE_NAME = 'data snapshot'"
echo $msnapshotsql >> /tmp/msnapshotsql.sql
echo $mcatid >> /tmp/mcatid.sql
hdbsql -U $SYSDBKEY -a -I /tmp/msnapshotsql.sql -o /tmp/msnapstart.log
hdbsql -U $SYSDBKEY -a -I /tmp/mcatid.sql -o /tmp/mcatid.log
mcid=`cat /tmp/mcatid.log`
xfs_freeze -f /hana/data
### cloud snapshot
gcloud compute disks snapshot <disk device name> --snapshot-names <snapshot name> --zone us-central1-b
xfs_freeze -u /hana/data
msnapclose="BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID $mcid SUCCESSFUL '$iPrefix' "
echo $msnapclose >> /tmp/msnapclose.sql
hbsql -U $SYSDBKEY -a -I -a -I /tmp/msnapclose.sql -o /tmp/mcatclose.logMethod 2 – Automate HANA snapshot using cloud console schedule snapshots.
# Kindly add necessary error handler as best practice
# iPrefix value from command line parameter
# SYSDBKEY value from command line parameter
DATE_TIME="`date \"+%Y%m%d_%H_%M_%S\"`"
iPrefix="$DATE_TIME"_"$iPrefix"
#
msnapshotsql="BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT '$iPrefix'"
mcatid="SELECT MAX(ENTRY_ID) FROM M_BACKUP_CATALOG WHERE ENTRY_TYPE_NAME = 'data snapshot'"
echo $msnapshotsql >> /tmp/msnapshotsql.sql
echo $mcatid >> /tmp/mcatid.sql
hdbsql -U $SYSDBKEY -a -I /tmp/msnapshotsql.sql -o /tmp/msnapstart.log
hdbsql -U $SYSDBKEY -a -I /tmp/mcatid.sql -o /tmp/mcatid.log
mcid=`cat /tmp/mcatid.log`
xfs_freeze -f /hana/data
sleep 15m
##### schedule cloud snapshot for /hana/data disk from cloud console - start/end during sleep time ######
xfs_freeze -u /hana/data
msnapclose="BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID $mcid SUCCESSFUL '$iPrefix' "
echo $msnapclose >> /tmp/msnapclose.sql
hbsql -U $SYSDBKEY -a -I -a -I /tmp/msnapclose.sql -o /tmp/mcatclose.logPoint-in-time Recovery using snapshots
Point-in-time recovery is based on specific scenario i.e. recovery on same server where database crashed and not available on secondary / DR etc OR entire region unavailability.
Scenario can be to build entire vm using OS disk + HANA disks snapshot. we tested with same scale-up database server recovery using snapshots.
What we recover from HANA/Cloud snapshot ?
- While executing HANA snapshot prepare step , HANA creates below highlighted content in one of HANA data directory. cloud snapshot includes this HANA setup in its snapshot. which later helps for point-in-time recovery.

- Next step is to decide which backup to use from HANA catalog. selecting backup from catalog is mandatory step when we do point-in-time recovery. if we don’t want point-in-time recovery – we can select specific backup recovery option. No delta / log backup consider for such recoveries.
Step by Step recovery process
- Rename existing /hana/data disk on server and create new /hana/data disk using selected hana backup respective cloud snapshot disk. kindly refer google cloud documentation.
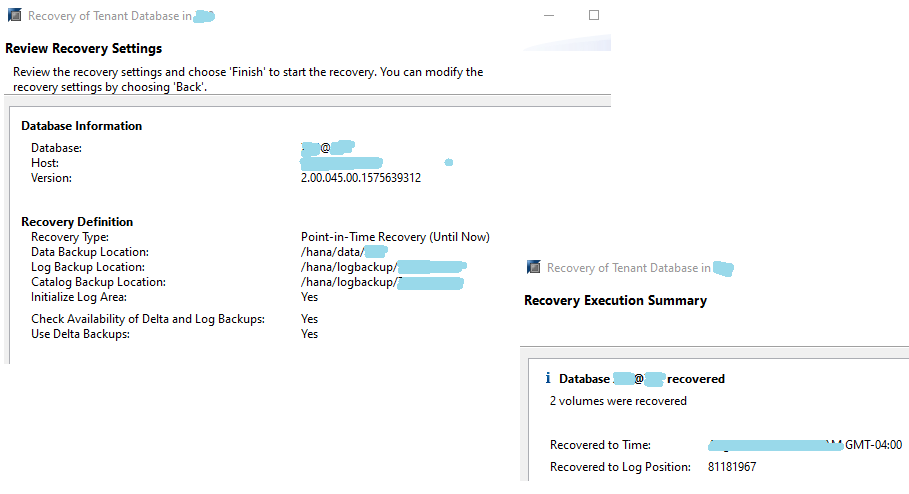
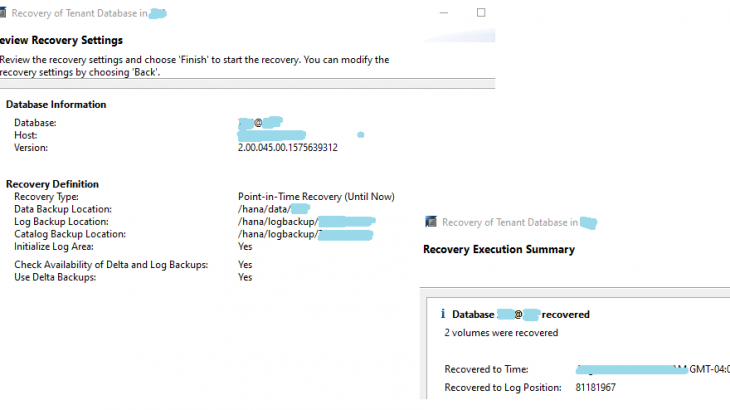
- Recover SYSTEM Database from snapshot – Select snapshot from catalog. backup must show as available like screen below.
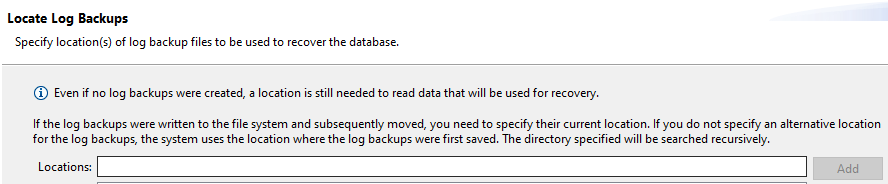
- Select log backup area for point-in-time recovery.
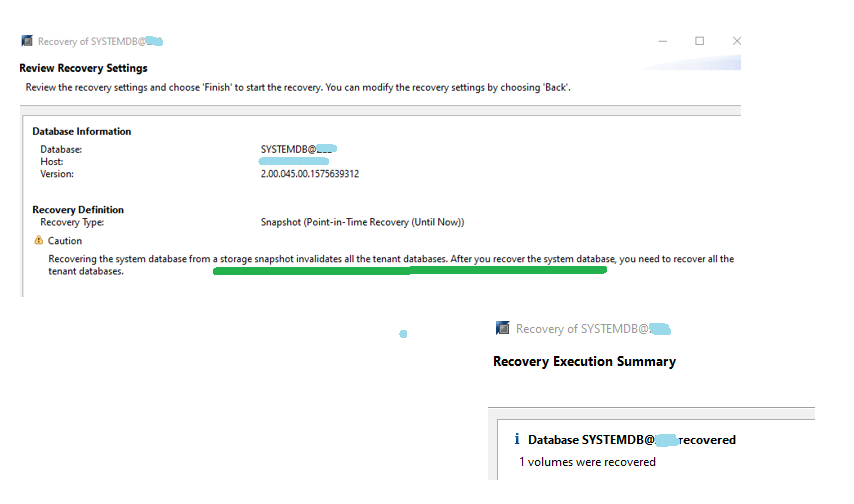
- SYSTEMDB Recovery Successful – Next task is to recover tenant database
- Recover Tenant database from same snapshot – Login to systemdb , trigger tenant recovery , Select available snapshot from catalog
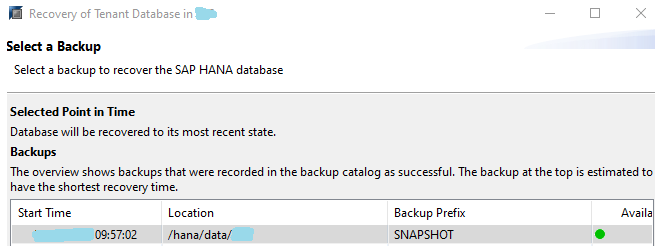
- Successful Tenant recovery