Machine learning algorithms such as linear regression, logistic regression, decision tree are very popular topic in today’s market. This article focused on anomaly detection with k-means algorithm by using outliers.
K-means algorithm may be used on diverse of use case scenarios from image compression to system monitoring applications. Identifying anomaly in daily CPU resource utilization trends can be given as a sample use-case. Traditional system monitoring applications use fixed threshold values to identify a bottleneck over the system. But regarding today’s requirements, it is not enough to monitor utilizations with fixed thresholds values. Monitoring system should to learn system resource utilization trends by using ML algorithms and create an alert in anomaly situation.
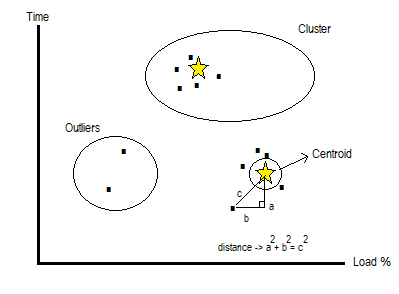
K-Means is a suitable solution for detecting anomalies in large data sets. Similarity analysis can be given as an example to detect anomalies in a dataset. In the example, two group of cars formed as two different clusters. Those clusters will have its own members in its immediate vicinity that is close similarity groups. If the element is close to the center of the cluster it becomes a group member. Elements far from the center, it identifies an anomaly situation for that cluster. If there is low similarity than those clusters, elements outside the clusters evaluates as an anomaly form.
K-means algorithm is basically based on Euclid calculation to measure distance of a tuple to centroid. This calculation repeating until distance values are being stable for each tuple. Please find k-Means visual sample on figure 1;
Figure 1
k-Means algorithm steps performed as below;
1- Assign each tuple to a randomly selected set
2- Calculate the centroid's distance from each cluster
3- Loop until there is no improvement or you reach the maxcount variable
4- Assign each tuple to the most appropriate cluster
5- Update cluster centroid
6- End loop
7- Return cluster information
HANA has its own k-means algorithm implementation in PAL library. This algorithm can be used easily by any kind of application that running a HANA system.
This article focused on k-Means outliers ABAP implementation without using HANA PAL library. Class has two main public functions. First one is “cluster” method. Second one is “outlier” method. In the cluster method, k-Means attribute values can be provided and assigned dynamically. It can have as many attributes as problem needs.
Dictionary objects:
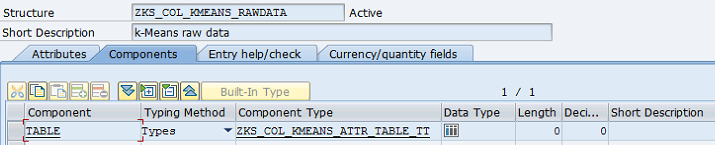
Before coding, data types need to be defined at ABAP dictionary level.
Table types:
Figure 2
Figure 3
Figure 4
Figure 5
Figure 6
Figure 7
Figure 8
Structures:
Figure 9
Figure 10
Figure 11
Figure 12
Figure 13
Test Program:
Dictionary objects figure 2, 3, 4, 5, 6, 7,8, 9, 10, 11, 12,13 should be created manually. Please find test program, below;
REPORT zkmeans_test.
TYPES: tt_atts TYPE STANDARD TABLE OF string WITH EMPTY KEY,
tt_rawdata TYPE TABLE OF zks_col_kmeans_rawdata WITH EMPTY KEY.
DATA: clustering TYPE REF TO zks_col_kmeans_clustering_tt,
outlier TYPE REF TO zks_col_kmeans_outlier_tt,
numattributes TYPE i,
numclusters TYPE i,
maxcount TYPE i,
lr_kmeans TYPE REF TO zcl_kmeans,
dataset TYPE tt_rawdata.
DATA(attributes) = VALUE tt_atts(
( `SampleAttribute1` )
).
dataset = VALUE #( ( table = VALUE #( ( value = 100 ) ) )
( table = VALUE #( ( value = 99 ) ) )
( table = VALUE #( ( value = 98 ) ) )
( table = VALUE #( ( value = 70 ) ) )
( table = VALUE #( ( value = 95 ) ) )
( table = VALUE #( ( value = 77 ) ) )
( table = VALUE #( ( value = 100 ) ) )
( table = VALUE #( ( value = 97 ) ) )
( table = VALUE #( ( value = 99 ) ) )
).
numattributes = lines( attributes ).
numclusters = 2.
maxcount = 30.
CREATE OBJECT lr_kmeans.
clustering = lr_kmeans->cluster(
rawdata = dataset
numclusters = numclusters
numattributes = numattributes
maxcount = maxcount ).
outlier = lr_kmeans->outlier(
rawdata = dataset
clustering = clustering
numclusters = numclusters
cluster = 0 ).
In example above, only one attribute with a few data provided into the cluster method. Sample test program source code has only one centroid to make it easy to understand. Of course this value can be increased regarding the requirements. Max count value has been set to 30, in test program. But the higher this value, the better results it produces. In the example, in order to identifiy outlier values on cluster, outlier method has been called after cluster method. As soon as outlier values has been identified by the outlier method, those values can be dropped out from provided dataset to filter noisy values.
Class Implementation:
There are two public methods on ABAP ZCL_KMEANS class; cluster and outlier. Other methods are utility functions that help to execute k-Means algorithm. Please find method signatures and implementations by description;
Name
CLUSTER
Description
Assign cluster node id to items in dataset
Level
Instance Method
Visibility
Public
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
NUMCLUSTERS
Importing
Type
INT4
NUMATTRIBUTES
Importing
Type
INT4
MAXCOUNT
Importing
Type
INT4
CLUSTERING
Importing
X
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
METHOD cluster.
DATA: changed TYPE boolean VALUE abap_true,
ct TYPE i VALUE 0,
numtuples TYPE i VALUE 0,
means TYPE REF TO zks_col_kmeans_means_tt,
centroids TYPE REF TO zks_col_kmeans_centroids_tt.
FIELD-SYMBOLS: <lr_rawdata> TYPE zks_col_kmeans_rawdata_tt.
numtuples = lines( rawdata ).
clustering = initclustering( numtuples = numtuples
numclusters = numclusters
randomseed = 0 ).
means = allocatemeans( numclusters = numclusters
numattributes = numattributes ).
centroids = allocatecentroids( numclusters = numclusters
numattributes = numattributes ).
ASSIGN rawdata TO <lr_rawdata>.
updatemeans( rawdata = <lr_rawdata>
clustering = clustering
means = means ).
updatecentroids( rawdata = rawdata
clustering = clustering
means = means
centroids = centroids ).
WHILE changed = abap_true AND ct < maxcount.
ct = ct + 1.
changed = Assign( rawData = rawData
clustering = clustering
centroids = centroids ).
UpdateMeans( rawData = rawData
clustering = clustering means = means ).
UpdateCentroids( rawData = rawData
clustering = clustering
means = means
centroids = centroids ).
ENDWHILE.
ENDMETHOD.
Name
OUTLIER
Description
Identify and return anomaly data in provided dataset
Level
Instance Method
Visibility
Public
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
CLUSTERING
Importing
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
NUMCLUSTERS
Importing
Type
INT4
CLUSTER
Importing
Type
INT4
OUTLIER
Returning
X
Type Ref To
ZKS_COL_KMEANS_OUTLIER_TT
METHOD outlier.
DATA: numattributes TYPE i VALUE 0,
means TYPE REF TO zks_col_kmeans_means_tt,
centroids TYPE REF TO zks_col_kmeans_centroids_tt,
total_dist TYPE i,
rawdatalength TYPE i,
i TYPE i VALUE 1,
c TYPE i,
dist TYPE i,
wa_outlier like LINE OF outlier->*.
numattributes = lines( rawdata[ 1 ]-table ).
FIELD-SYMBOLS: <lr_rawdata> TYPE zks_col_kmeans_rawdata_tt.
CREATE DATA outlier.
means = allocatemeans( numclusters = numclusters
numattributes = numattributes ).
centroids = allocatecentroids( numclusters = numclusters
numattributes = numattributes ).
ASSIGN rawdata TO <lr_rawdata>.
updatemeans( rawdata = <lr_rawdata>
clustering = clustering
means = means ).
updatecentroids( rawdata = rawdata
clustering = clustering
means = means
centroids = centroids ).
rawdatalength = lines( rawdata ) + 1.
WHILE i NE rawdatalength.
c = clustering->*[ i ]-id.
IF c EQ cluster.
dist = distance( tuple = rawdata[ i ]-table vector =
centroids->*[ cluster + 1 ]-table ).
total_dist = total_dist + dist.
ENDIF.
i = i + 1.
ENDWHILE.
total_dist = total_dist / rawDataLength.
i = 1.
WHILE i NE rawdatalength.
c = clustering->*[ i ]-id.
IF c EQ cluster.
dist = distance( tuple = rawdata[ i ]-table vector =
centroids->*[ cluster + 1 ]-table ).
If dist > total_dist.
wa_outlier-table = rawdata[ i ]-table.
APPEND wa_outlier to outlier->*.
EndIf.
ENDIF.
i = i + 1.
ENDWHILE.
ENDMETHOD.
Name
INITCLUSTERING
Description
Create and initialize clustering internal table with randomized values for each centroid id and assign “0” value to its data field. Each row has been assigned to a cluster id in dataset in this array
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
NUMTUPLES
Importing
Type
INT4
NUMCLUSTERS
Importing
Type Ref To
INT4
RANDOMSEED
Importing
Type
INT4
CLUSTERING
Returning
X
Type
ZKS_COL_KMEANS_CLUSTERING_TT
METHOD initclustering.
FIELD-SYMBOLS: <clustering> TYPE zks_col_kmeans_clustering_tt.
DATA: lv_random TYPE REF TO cl_abap_random_int,
lv_wa_clustering LIKE LINE OF <clustering>,
lv_counter TYPE i.
lv_random = cl_abap_random_int=>create( seed = CONV i( sy-uzeit )
min = 0
max = numclusters - 1 ).
CREATE DATA clustering.
ASSIGN clustering->* TO <clustering>.
lv_counter = 0.
WHILE lv_counter NE numclusters.
lv_wa_clustering-id = lv_counter.
APPEND lv_wa_clustering TO <clustering>.
lv_counter = lv_counter + 1.
ENDWHILE.
WHILE lv_counter LE numtuples - 1.
lv_wa_clustering-id = lv_random->get_next( ).
APPEND lv_wa_clustering TO <clustering>.
lv_counter = lv_counter + 1.
ENDWHILE.
ENDMETHOD.
Name
ALLOCATECENTROIDS
Description
Create and initialize centroid value internal table
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
NUMTUPLES
Importing
Type
INT4
NUMCLUSTERS
Importing
Type
INT4
CENTROIDS
Returning
X
Type Ref To
ZKS_COL_KMEANS_CENTROIDS_TT
METHOD allocatecentroids.
DATA: lv_wa_centroids LIKE LINE OF centroids->*,
lr_attributes TYPE REF TO zks_col_kmeans_attr_table_tt,
wa_attributes LIKE LINE OF lr_attributes->*,
lv_cluster_counter TYPE i VALUE 0,
lv_attribute_counter TYPE i VALUE 0.
CREATE DATA centroids.
WHILE lv_cluster_counter NE numclusters.
CREATE DATA lr_attributes.
WHILE lv_attribute_counter NE numattributes.
APPEND wa_attributes TO lr_attributes->*.
lv_attribute_counter = lv_attribute_counter + 1.
ENDWHILE.
MOVE lr_attributes->* TO lv_wa_centroids-table.
APPEND lv_wa_centroids TO centroids->*.
lv_cluster_counter = lv_cluster_counter + 1.
lv_attribute_counter = 0.
ENDWHILE.
ENDMETHOD.
Name
ALLOCATEMEANS
Description
Create and initialize mean value internal table
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
NUMTUPLES
Importing
Type
INT4
NUMCLUSTERS
Importing
Type
INT4
MEANS
Returning
X
Type Ref To
ZKS_COL_KMEANS_MEANS_TT
METHOD allocatemeans.
DATA: lv_wa_means LIKE LINE OF means->*,
lr_attributes TYPE REF TO zks_col_kmeans_attr_table_tt,
wa_attributes LIKE LINE OF lr_attributes->*,
lv_cluster_counter TYPE i VALUE 0,
lv_attribute_counter TYPE i VALUE 0.
CREATE DATA means.
WHILE lv_cluster_counter NE numclusters.
CREATE DATA lr_attributes.
WHILE lv_attribute_counter NE numattributes.
APPEND wa_attributes TO lr_attributes->*.
lv_attribute_counter = lv_attribute_counter + 1.
ENDWHILE.
MOVE lr_attributes->* TO lv_wa_means-table.
APPEND lv_wa_means TO means->*.
lv_cluster_counter = lv_cluster_counter + 1.
lv_attribute_counter = 0.
ENDWHILE.
ENDMETHOD.
Name
UPDATEMEANS
Description
Update mean values
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
CLUSTERING
Importing
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
MEANS
Importing
X
Type Ref To
ZKS_COL_KMEANS_MEANS_TT
METHOD updatemeans.
DATA: numclusters TYPE i,
wa_means LIKE LINE OF means->*,
lr_attributes TYPE REF TO zks_col_kmeans_attr_table_tt,
wa_attributes LIKE LINE OF lr_attributes->*.
FIELD-SYMBOLS: <fs> TYPE zks_col_kmeans_attr_table_tt.
numclusters = lines( means->* ).
LOOP AT means->* INTO wa_means.
ASSIGN wa_means-table TO <fs>.
LOOP AT <fs> INTO wa_attributes.
wa_attributes-value = 0.
MODIFY <fs> FROM wa_attributes.
ENDLOOP.
MODIFY means->* FROM wa_means.
ENDLOOP.
DATA: clustercounts TYPE STANDARD TABLE OF i WITH EMPTY KEY,
countnumclusters TYPE i,
rawdatalength TYPE i VALUE 0,
i TYPE i VALUE 1, " cluster array index start with 1
j TYPE i VALUE 1, " means array index start with 1
k TYPE i VALUE 1, " means array index start with 1
l TYPE i VALUE 1, " means array index start with 1
cluster TYPE i,
meanslength TYPE i VALUE 0,
meansattributeslength type i value 0,
rawdataattributeslength type i value 0.
WHILE numclusters NE countnumclusters.
APPEND 0 TO clustercounts.
countnumclusters = countnumclusters + 1.
ENDWHILE.
rawdatalength = lines( rawdata ) + 1.
WHILE i NE rawdatalength.
cluster = clustering->*[ i ]-id + 1.
clustercounts[ cluster ] = clustercounts[ cluster ] + 1.
j = 1.
rawdataattributeslength = lines( rawdata[ i ]-table ) + 1.
WHILE j NE rawdataattributeslength.
means->*[ cluster ]-table[ j ]-value =
means->*[ cluster ]-table[ j ]-value +
rawdata[ i ]-table[ j ]-value.
j = j + 1.
ENDWHILE.
i = i + 1.
ENDWHILE.
meanslength = lines( means->* ) + 1.
WHILE k NE meanslength.
meansattributeslength = lines( means->*[ k ]-table ) + 1.
l = 1.
WHILE l NE meansattributeslength.
means->*[ k ]-table[ l ]-value =
means->*[ k ]-table[ l ]-value / clustercounts[ k ].
l = l + 1.
ENDWHILE.
k = k + 1.
ENDWHILE.
ENDMETHOD.
Name
UPDATECENTROIDS
Description
Update centroid values
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
CLUSTERING
Importing
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
MEANS
Importing
Type Ref To
ZKS_COL_KMEANS_MEANS_TT
CENTROIDS
Importing
Type Ref To
ZKS_COL_KMEANS_CENTROIDS_TT
METHOD updatecentroids.
DATA: centroidslenght TYPE i VALUE 0,
k TYPE i VALUE 1, " means array index start with 1
centroid TYPE REF TO zks_col_kmeans_centroids_tt.
centroidslenght = lines( centroids->* ) + 1.
WHILE k NE centroidslenght.
centroid = computecentroid( rawdata = rawdata
clustering = clustering
cluster = k - 1
means = means ).
centroids->*[ k ]-table = centroid->*[ 1 ]-table.
k = k + 1.
ENDWHILE.
ENDMETHOD.
Name
ASSIGN
Description
Update centroid values
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
CLUSTERING
Importing
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
CENTROIDS
Importing
Type Ref To
ZKS_COL_KMEANS_CENTROIDS_TT
CHANGED
Returning
X
Type
ABAP_BOOL
METHOD assign.
DATA: numclusters TYPE i VALUE 0,
distances TYPE zks_col_kmeans_distances_tt,
wa_distances LIKE LINE OF distances,
distancescounter TYPE i VALUE 0,
rawdatalength TYPE i VALUE 0,
i TYPE i VALUE 1,
k TYPE i VALUE 1,
newcluster TYPE i VALUE 0.
numclusters = lines( centroids->* ).
WHILE distancescounter NE numclusters.
APPEND wa_distances TO distances.
distancescounter = distancescounter + 1.
ENDWHILE.
rawdatalength = lines( rawdata ) + 1.
WHILE i NE rawdatalength.
k = 1.
WHILE k NE numclusters + 1.
distances[ k ] = distance( tuple = rawdata[ i ]-table
vector = centroids->*[ k ]-table ).
k = k + 1.
ENDWHILE.
newcluster = minindex( distances = distances ).
IF newcluster <> clustering->*[ i ]-id.
changed = abap_true.
clustering->*[ i ]-id = newcluster.
ENDIF. " else no change
i = i + 1.
ENDWHILE.
ENDMETHOD.
Name
DISTANCE
Description
Measure distance from data to centroid by using Euclid calculation
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
TUPLE
Importing
Type
ZKS_COL_KMEANS_ATTR_TABLE_TT
VECTOR
Importing
Type
ZKS_COL_KMEANS_ATTR_TABLE_TT
RETVAL
Returning
Type
INT4
METHOD distance.
DATA: sumsquareddiffs TYPE i VALUE 0,
tuplelength TYPE i,
j TYPE i VALUE 1,
power TYPE i VALUE 0.
tuplelength = lines( tuple ) + 1.
WHILE j NE tuplelength.
power = ipow( base = tuple[ j ]-value - vector[ j ]-value exp = 2 ).
sumsquareddiffs = sumsquareddiffs + power.
j = j + 1.
ENDWHILE.
retval = sqrt( sumsquareddiffs ).
ENDMETHOD.
Name
MININDEX
Description
Cluster id of the cluster that has centroid closest to the tuple
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
DISTANCES
Importing
Type
ZKS_COL_KMEANS_DISTANCES_TT
NEWCLUSTER
Returning
Type
INT4
METHOD minindex.
DATA: indexofmin TYPE i VALUE 0,
smalldist TYPE i VALUE 0,
k TYPE i VALUE 1,
distanceslength TYPE i VALUE 0.
distanceslength = lines( distances ) + 1.
smalldist = distances[ 1 ].
WHILE k NE distanceslength.
IF distances[ k ] < smalldist.
smalldist = distances[ k ].
indexofmin = k - 1.
ENDIF.
k = k + 1.
ENDWHILE.
newcluster = indexofmin.
ENDMETHOD.
Name
COMPUTECENTROID
Description
Determine centroid values
Level
Instance Method
Visibility
Private
Parameter
Type
Pass By Value
Typing Method
Associated Type
RAWDATA
Importing
Type
ZKS_COL_KMEANS_RAWDATA_TT
CLUSTERING
Importing
Type Ref To
ZKS_COL_KMEANS_CLUSTERING_TT
CLUSTER
Importing
Type
INT4
MEANS
Importing
Type Ref To
ZKS_COL_KMEANS_MEANS_TT
CENTROID
Importing
X
Type Ref To
ZKS_COL_KMEANS_CENTROIDS_TT
METHOD computecentroid.
DATA: numattributeslength TYPE i,
rawdatalength TYPE i,
i TYPE i VALUE 1,
j TYPE i VALUE 1,
mindist TYPE f VALUE '1.7976931348623157E+308',
attributecounter TYPE i,
wa_centroid LIKE LINE OF centroid->*,
centroidlength TYPE i,
attributes TYPE REF TO zks_col_kmeans_attr_table_tt,
wa_attributes LIKE LINE OF attributes->*.
numattributeslength = lines( means->*[ 1 ]-table ).
rawdatalength = lines( rawdata ) + 1.
CREATE DATA attributes.
WHILE attributecounter NE numattributeslength.
APPEND wa_attributes TO attributes->*.
attributecounter = attributecounter + 1.
ENDWHILE.
CREATE DATA centroid.
wa_centroid-table = attributes->*.
APPEND wa_centroid TO centroid->*.
WHILE i NE rawdatalength.
DATA: c TYPE i.
c = clustering->*[ i ]-id.
IF c EQ cluster.
DATA currdist TYPE f.
currdist = distance( tuple = rawdata[ i ]-table
vector = means->*[ cluster + 1 ]-table ).
IF currdist < mindist.
mindist = currdist.
centroidlength = lines( centroid->*[ 1 ]-table ) + 1.
j = 1.
WHILE j NE centroidlength.
centroid->*[ 1 ]-table[ j ]-value =
rawdata[ i ]-table[ j ]-value.
j = j + 1.
ENDWHILE.
ENDIF.
ENDIF.
i = i + 1.
ENDWHILE.
ENDMETHOD.
Asymptotic Time Complexity:
Please find asymptotic time complexity analysis results of methods in K-Means class, below;