
HANA the “Hot cake” of the market. I have been hearing about HANA since the beginning of this decade or even earlier. Initially I thought it was just a new database, so why the fuss? My crooked mind used to say: may be SAP does not want to share the market revenue with any other database provider (competitors); therefore they came up with their own database.
Later I had a notion that HANA is only for BI/BW folks, so being an ABAPer – why should I care? Everyone used to talk about analysis and modelling. So, I used to think, let the BI/BW modelers worry about HANA.
Then the rumour started in market; ABAP and ABAPer are going to be extinct in near future. I used to wonder, if ABAPer are going to die, then who in this whole universe would support those tons and tons of ABAP code written in the history of SAP Implementations? What will happen to all those time, effort and money spent in those large and small scales SAP Implementations? What a waste of rumour!!
I have spent more time in researching what is HANA than actually learning what HANA is. Internet is full of information regarding HANA but finding the right answers for your curiosity or doubt, is an uphill task.
I had some silly questions for HANA but felt a little embarrassed to ask the experts. I spent and wasted lots of time trying to figure out what is HANA and who needs it and why?
Some of the questions which I had and I am sure all novice in HANA would have the same are below:
Q. Is SQL a pre-requisite to learn HANA?
Q. Without SAP BI/BW/BO knowledge, can I learn HANA?
Q. Is SAP ABAP skilled required to learn HANA?
Q. Is HANA for functional folk or technical folks or modelers?
Please find answers to these SAP HANA doubts from a beginner in HANA to another beginner in HANA. They might not be very technical or in-depth, but it would definitely be enough for a beginner and I am sure the new comers would appreciate these selective information.
Q. Is SQL a pre-requisite to learn HANA? (Being an ABAPer, this was one of the most feared question for me)
Ans: No.
SAP HANA is like any other relational database. Having Database Concepts and basic knowledge of SQL before starting SAP HANA is an advantage, but it is not a pre-requisite. You can always catch up with these concepts while learning SAP HANA.
Q. Without SAP BI/BW/BO knowledge, can I learn HANA? (I am sure all ABAPers have this question)
Ans: Yes.
BI is the Data Warehousing package implementation tool from SAP. Data Warehousing Concepts in SAP BI will help understand the implementation aspects from BW on HANA perspective. But unless you plan to a BW on HANA consultant, you necessarily do not have to learn BI.
Similarly BW and BO are Business Warehouse and Business Object respectively. If you have prior BW experience, understanding modeling concept and transferring data SAP Business Suite System to HANA would be child’s play for you. But, we can easily learn HANA modeling concept even if we do not have current exposure to BW. But it would be a must for those consultants who are eyeing the role of BW on HANA expert.
By now, I have understood that BO is a front end reporting tool. Prior knowledge in reporting tools would be an advantage but, we can always learn BO concepts while learning HANA.
But, if you already have BI/BW/BO knowledge, then BW on HANA work would be the role you would be targeting to (if you are planning to shift to HANA).
Q. Is SAP ABAP skilled required to learn HANA?
Ans: No.
Whatever we said above for BI/BW/BO is applicable to ABAP as well.
If you are an SAP ABAP programmer, then implementing the business logic and model would be fun for you. You must have already heard about SAP ABAP on HANA. Let’s put a full stop to the rumour that ABAPer are vanishing. With HANA, ABAPer would be smarter and more in demand. Only ABAP on HANA consultant would need ABAP knowledge as pre-requisite.
Q. Is HANA for functional folk or technical folks or modelers?
Ans: All.
Like any other technology, HANA also has segregation of duty, therefore the answer to this question is ‘ALL’. Some of the HANA job roles are as below:
i) HANA Admin and Security
Our current SAP Basis/Security/GRC guys would be the nearest cousins of HANA Admin and Security folks.
ii) HANA Data Replicator
Like in normal SAP Implementation project we have Conversion and Interface team and experts, the HANA Data Replication role would be similar to that. SAP BI/BO guys are the closest. They will use jargons like SLT, BODS, DXC etc.
SLT = SAP Landscape Transformation
BODS = Business Objects Data Services
DXC = Direct eXtractor Connection
iii) HANA Modeler
SAP BW gurus are already modeling, so will SAP HANA Modelers.
iv) HANA Application Developer
HANA XS or ABAP on HANA Developers.
Further, I had some other curious questions, a little more technical like:
Q. HANA means in-memory. In-memory means RAM. We all know, RAM is volatile temporary memory. Does it mean all data would be lost when power goes down, or there is reboot etc i.e. if there is a hard or soft failure?
Ans: No. SAP must have thought this even before they started the development. (I cannot be smarter than SAP)
Data is stored in RAM, that is right. But on power failure for any reason, data is not lost. Here comes the concept of Persistent Storage.
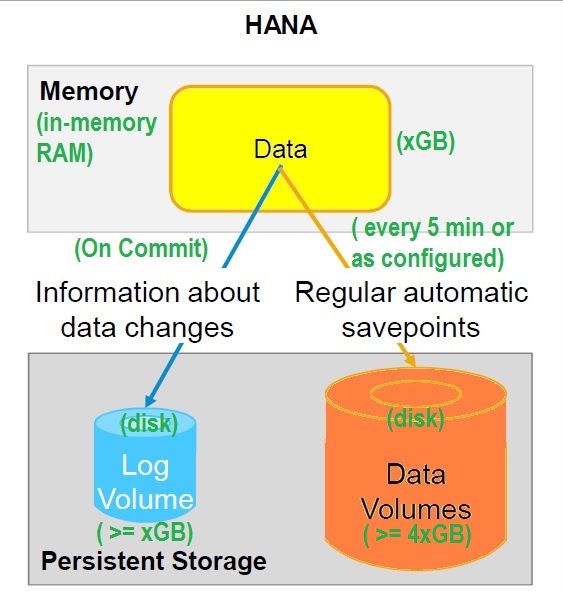
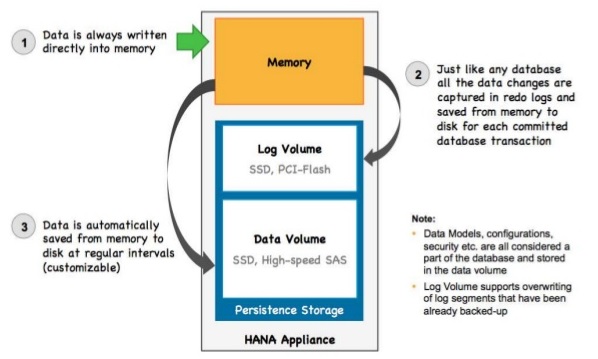
Transaction data is updated to Log Volume on every commit. Data is saved to Data Volume every 300 sec or as configured. These create savepoints.
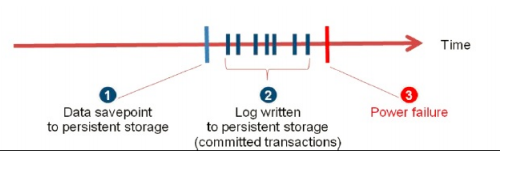
In case of reboot or power start up, system can be taken back to last consistent save point and then replay the Log Volume committed data.
Q. SAP HANA claims to be so fast. Which programming language is it written in?
Ans: World famous C++.
Q. What is the Operating System of SAP HANA?
Ans: Suse Linux Server SPX & Red Hat linux Server 6.5
Q. Another question which I always had was, if HANA is about RAM, so can we increase the memory size of traditional database and get similar performance like HANA?
Ans: No.
We would definitely get better performance if we increase the memory size of traditional database, but it would not be comparable to what we get in HANA. But Why?
Because, HANA is not just about database. It is a hybrid in-memory database which is combination of niche Hardware and Software innovation as stated below:
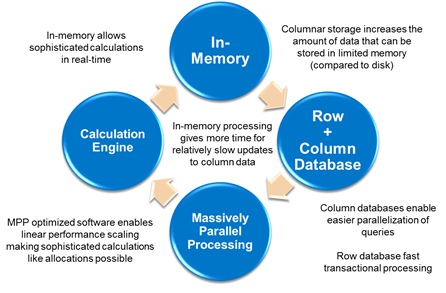
In-Memory storage (RAM): Processing data from RAM itself is 1 million time faster than accessing data from hard disk. In practical scenarios, it might is around 10x to 3600x time faster. Also, in today’s world RAM is cheap and affordable expense wise.
Trivia: Read time in RAM: 2 MB/ms/core (2 megabyte per millisecond per core).
So to scan 1 GB of data, it would approximately take 0.5 s/core. For 100 GB it would take 50 s/core. If you have 50 cores in the hardware, scanning 100 GB data would take just 1 second. Huh!! Quantitative numbers always clarifies better than paragraphs of sentences. Isn’t it?
Multi core Architecture, Partitioning & Enormous Parallel Processing: Servers are available with one node up to 64 cores (and even more). So partitioning the data foot prints in different node and running the query parallel is the innovation which HANA uses so effectively. This is perfect example of both hardware and software innovation.
Columnar Storage: Contiguous memory allocation
Faster reading with sequential memory access. Remember, column store not only makes reading faster. HANA has built the column store is such a way that it is efficient for both READ and WRITE.
Quick aggregation (normally aggregation are expensive) and also supports parallel processing.
Searching in column store is must faster than row storage (provided you are selecting only some sets of columns, not all).
Data Compression: Minimize data footprint through Compression i.e. less data movement means faster performance.
Idea is remove repetitive data, build a vector for the data and point it with an integer (and integer is less expensive than reading a string).
Q. Ok heard enough of Column Store in HANA. But, how does Column Storage actually make it faster?
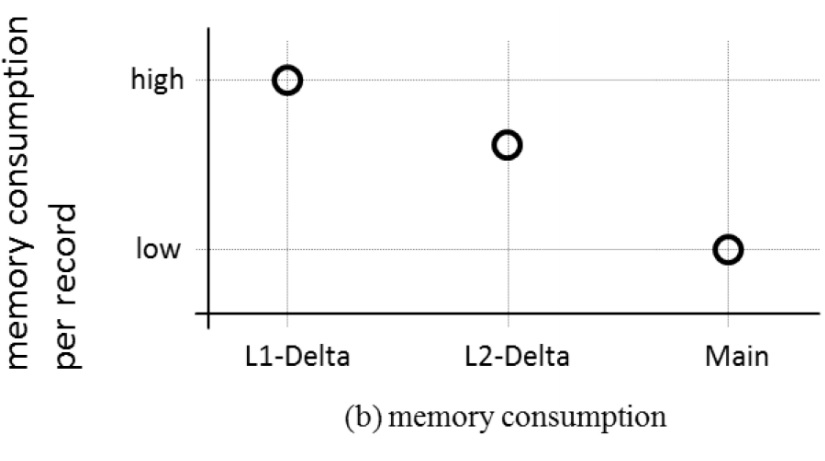
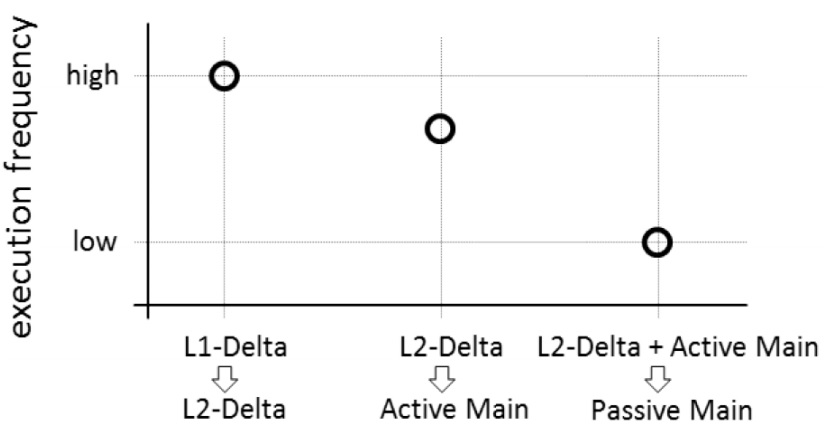
Ans: Column store is divided into three parts: i) Main ii) L2 Delta iii) L1 Delta/cache Persisted data are saved in Main Memory, all buffer and transaction changes are kept in L2 Delta and High Inserts / Deletes / Updates etc in L1 Delta
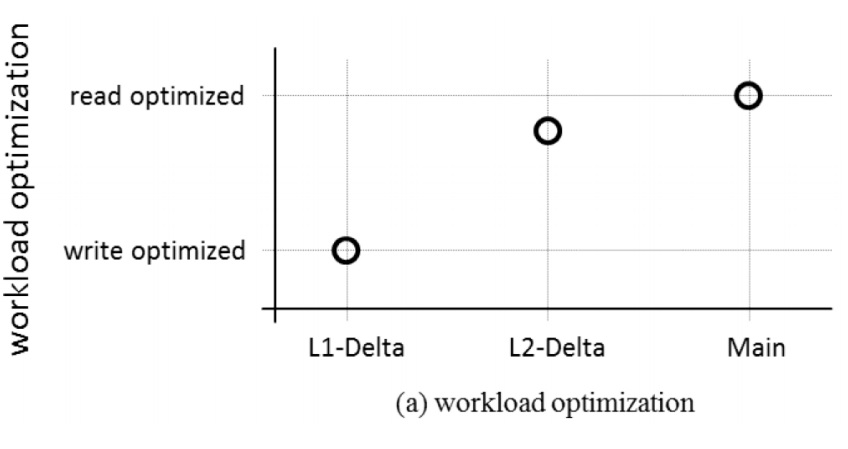
L1-delta
– accepts all incoming data requests
– stores records in row format (write-optimized)
• fast insert and delete
• fast field update
• fast record projection
– no data compression
– holds 10,000 to 100,000 rows per single-node
L2-delta
– the second stage of the record life cycle
– stores records in column format
– dictionary encoding for better memory usage
– unsorted dictionary
• requiring secondary index structures to optimally
support point query access patterns
– well suited to store up to 10 million rows
Main
– final data format
– stores records in column format
– highest compression rate
• sorted dictionary
• positions in dictionary stored in a bit-packed manner
• the dictionary is also compressed
So the smart innovation of L1, L2 and Main memory and combination of all three, make data read and write, really fast and effective.
These are some of the obvious questions, which almost all beginners in SAP HANA have. I had to dig through different sources to collect and understand these concepts. Hope all these information at one place would help you to understand it better.









