Introduction
As known from many articles and publications, SAP offers three solutions for data warehousing.
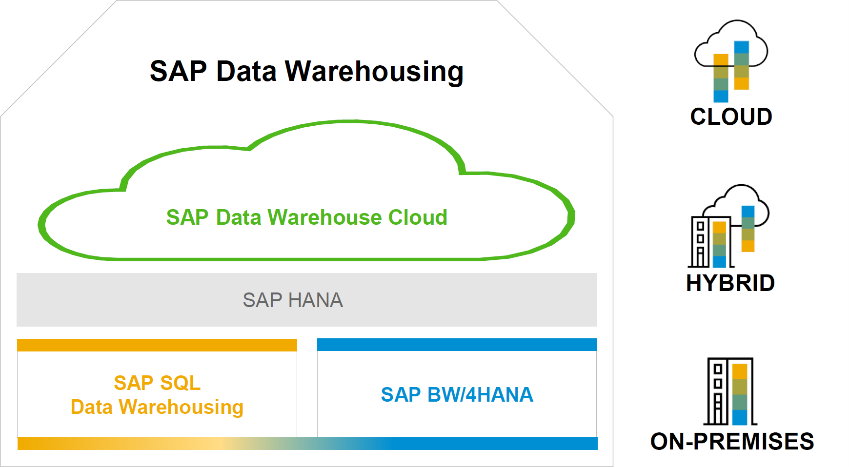
The SAP Business Warehouse (BW) was first published in 1997 and has therefore been a constant figure in the SAP Data Warehouse range for more than two decades. BW / 4 HANA as a HANA-optimized variant integrates the old ABAP world with the new SQL orientation of the SAP HANA platform.
With HANA as a database platform, the HANA SQL Data Warehouse approach has been developing since 2015, which initially consisted of loosely coupled tools, but has since evolved into an open, yet highly integrated set of tools and methods, that can also be used to develop large data warehouse systems.
Since 2019, the Data Warehouse Cloud has been completing the SAP solution as a SaaS solution.
These three approaches are not in competition. They differ very clearly in their properties, methods and tools, so that an optimized solution approach can be found depending on the individual company situation, which may also consist of a combination of the three alternatives.
In this blog I would like to introduce the HANA SQL Data Warehouse approach and first of all focus on what characterizes this approach in particular. In later blog posts I will then further explain the various aspects in greater depth. Writing this article my intent is to illustrate approaches to data warehousing to interested readers who may not be familiar with them yet.
The most important features of a HANA SQL data warehouse are:
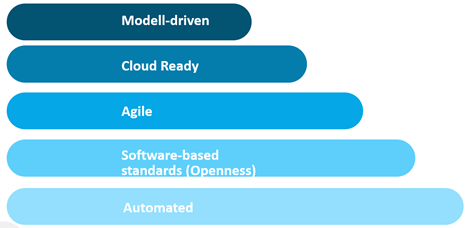
Modell-driven
Model-driven development means that data models are at the centre of development. Both the business-oriented conception and the design of the physical database objects are based on corresponding data models. The structures of the source system are also documented in corresponding data models using reverse engineering.
All data models are modelled with the SAP Power Designer, which is characterized by a high level of integration with SAP HANA. HANA CDS artifacts or HANA tables can be generated from the physical data models.
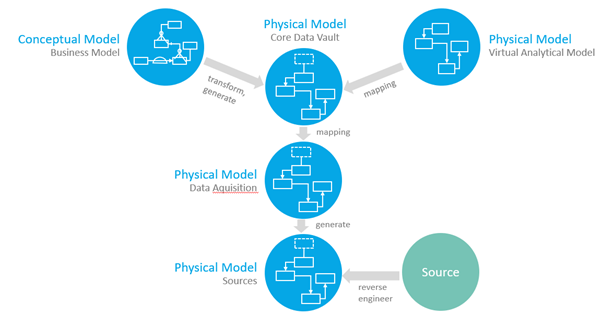
Conceptual model (business model)
With a top-down approach, the business model forms the starting point for modelling on a conceptual level. On this level the view of the business on the analytical world is modelled. Methodology is the Entity-Relationship method, which represents the entities with their properties and the relationships between the entities. A clean modelling of the business view already lays the foundation for a high quality of the data warehouse.
Core data warehouse (physical model)
The central data warehouse model can be derived from the business model. This represents the persistent core of the data warehouse. Basically, you are free to choose between the modelling methodology, the 3rd NF, dimensional modelling or the Data Vault method. Based on practical experience, the Data Vault method is recommended due to its agility. It has proven itself in our large DWH projects.
Data source model / stage model (physical model)
Based on the source system structures, the data source model can be generated by reverse engineering and the stage model can be derived from this. These two models are necessary if you want to enable a data lineage from the analytical information to the source system.
Virtual Analytical Model (Physical Model)
The analytical objects via which the users consume the analytical information are illustrated in this model. These are usually the calculation views that the user accesses.
As can be seen in the graphic, all models are linked to one another by mappings. This makes the relationships between the models clear and gives you the option of data lineage.

Cloud ready
SAP is developing more and more into a cloud company. This is shown e.g. in the development of Data Warehouse Cloud. The technical basis for this is the HANA Cloud. Due to the consistent focus on the cloud, the cloud orientation is becoming increasingly important in data warehouse development.
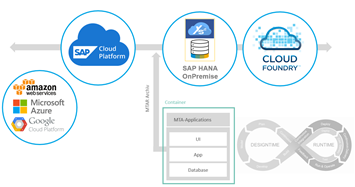
This shows a great advantage of the HANA SQL Data Warehouse. The central development environment is the SAP HANA Extended Application Services Advanced (XSA). SAP HANA XSA is based on the Cloud Foundry architecture and, together with the SAP HANA Deployment Infrastructure (HANA DI), is the reason for the development of SAP HANA away from a pure database towards a platform technology.
By containerizing the developments in so-called MTAR archives, they can be easily moved back and forth between on-premise (XSA) and cloud environments (Cloud Foundry) (Figure 1.2). The SAP HANA SQL Data Warehouse is therefore completely independent of the underlying technical infrastructure. This does not only apply to the database artifacts. Because the SAP HANA platform offers the possibility to develop full-stack application or UI5 applications, those applications can also be exchanged separately between the on-premise and cloud platform.

Agile
Agile development approaches and methods have shaped the software industry since the late 1990s and are now part of the standard of the IT industry. Even if the area of data warehousing in the sense of adoption theory is to be seen as a “late majority” in relation to this innovation. The development approaches in this area have shifted strongly in the direction of agile in recent years. In this context, the DevOps philosophy in particular plays a decisive role.
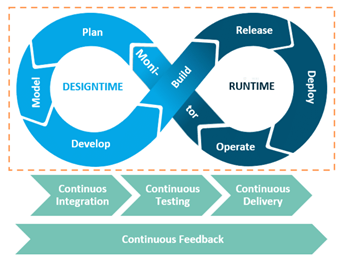
For our approach to agile SAP HANA SQL data warehousing, we have adapted the classic DevOps loop according to our work steps, as it differs a little from the basic concept of software development in the data warehouse context (Figure 01). In the following we describe the eight phases of design (dev) and runtime (ops). In the future parts of this series I will explain more about the presentation of the agile process model and the higher-level continuity processes. The following continuity processes play an important role here:
- Continuous Integration (CI)
- Continuous Delivery (CD)
- Continuous Testing (CT)
- Continuous Feedback
The central aspect of the agile approach is to ensure smaller delivery units in short cycles and to accelerate the associated development process through a high degree of automation.

Software Base Standards (Openness)
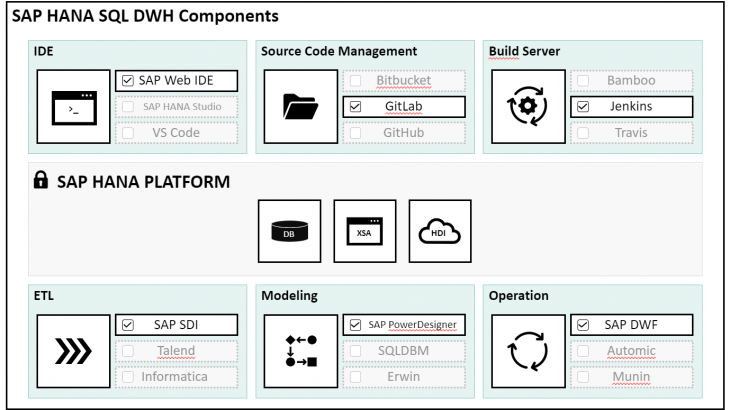
As we saw in the previous section “Agile”, we orientate ourselves towards the methods of software development when developing a HANA SQL data warehouse. In order to be able to apply the methods, we have to supplement the data warehouse-specific tools such as ETL or data modelling tools with tools that support an agile development process. Here we can use tools that are common in classic software development, such as GIT for source code and version management, Jenkins / Bamboo to support the continuity processes, Moccha as a framework for test automation. I will also go into these tools in more detail when I specifically present the continuity processes in future blogs.
Here, as well, a special characteristic of the HANA SQL data warehouse approach is evident. In order to be able to integrate these tools into the development process, an openness regarding the integration of other tools, especially also open source tools, is required. This openness is due to the HANA platform and the use of the XSA as a central development platform. Thus, there is great freedom in the choice of tools. They become interchangeable. The following illustration gives an exemplary overview of the HANA SQL data warehouse components and their interchangeability.
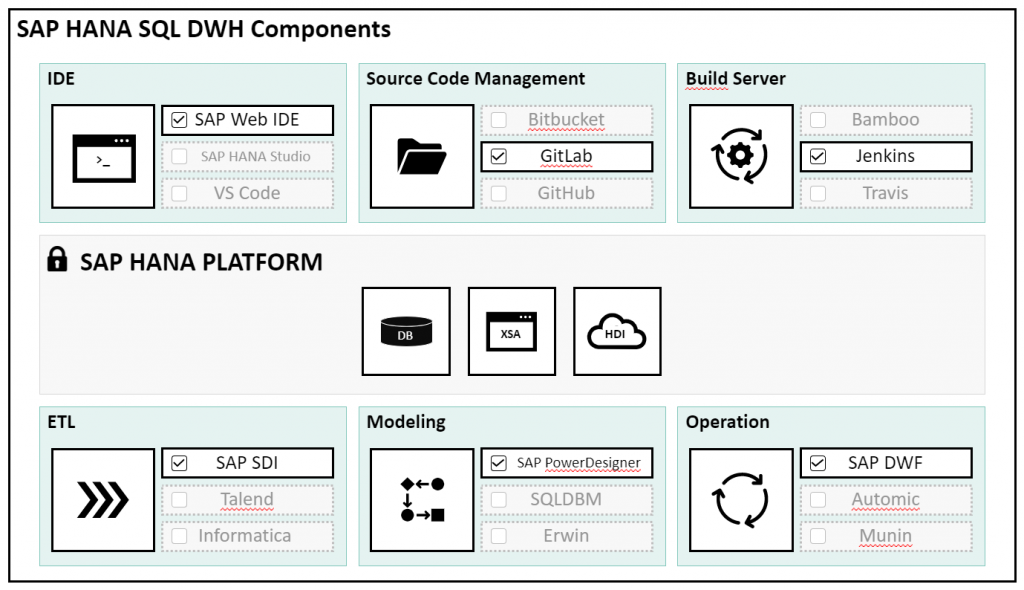
In addition to the integration of open source tools, the fact that we develop purely SQL-based also plays an important role. This means that we are using tools that, at their core, understand and execute SQL. This distinguishes the HANA SQL approach from the BW / 4 approach, which is based on ABAP. Basically, we can integrate all tools that are SQL based. Examples are the ETL tools Informatica and Talend, which can basically be used for ETL like the HANA-specific tool SDI. This scenario is also used in migration scenarios in which a non-SAP SQL database is migrated to HANA and the ETL management is continued with the existing ETL tool.

Automation
A very important requirement for a modern data warehouse is agility. This should shorten development cycles and thus enable a faster time2market. An important building block is the automation of development processes.
Automation first requires a fundamental structuring of the data warehousing processes. Even today, data warehousing is often a multi-layered area in which different tools are used by different stakeholders. Therefore, with regard to the automation of individual tasks, it is important to put the development work on the data warehouse into a uniform corset and to clearly define the interlocking of the individual activities. The goal of automation is to replace manual activities, which occur repeatedly during the development and implementation of a data warehouse and make up a large part of the work volume, with automated software processes. In this way, data warehousing is to be simplified and accelerated and conceptually transferred into a lifecycle management that provides for clearly defined and largely automated steps for the development, maintenance and further development of a data warehouse.
Areas of Automation
After these rather fundamental, but nevertheless important aspects of data warehouse automation, the question arises as to the concrete activities that can be automated. The following work steps and processes can be named:
Connection of source systems
The connection of the source systems is a process that can be automated to a large extent through so-called reverse engineering. In reverse engineering, the metadata of the source systems, i.e. the data that provides information about the way the data is organised in the respective source system, is read out and is available for further processing in the data warehouse. In this way, the source connection takes a central position with regard to the preparation of the different data models in the data warehouse, since the metadata of the source systems serve as a basis that is merely converted or extended and supplemented according to specific rules.
Object generation
Object generation refers to the individual elements in the different data models of the data warehouse. The different data models result from the layer architecture of a data warehouse, which usually consists of two or three layers. The Data Vault data model is usually at the centre. It specifies the essential rules based on the real business conditions. The definition of the concrete rules can therefore not be automated. However, once this work has been done, a large part of all objects can be generated automatically in conjunction with the metadata of the source systems.
ETL Generation
In classic data warehousing, the data is transferred from OLTP systems to the OLAP system of the data warehouse by extract, transform and load (ETL). More modern solutions also work with virtual connections, in which the data is available in the data warehouse but physically remains in the source system. In both cases, the data flows must be designed. Through DWA, with the previous steps of source connection and object generation, this work can also be highly automated as a waste product.
Continuous Integration, Testing und Delivery
Continuous Integration, Continuous Testing and Continuous Delivery are terms used in agile software development and today are specifically associated with the DevOps philosophy. In combination, these continuity processes intend to continuously integrate smaller developments or development stages and deliver them to productive environments in order to achieve usable added value as quickly as possible or to uncover undesirable developments as quickly as possible. An important factor here is the highest possible degree of automation, especially with regard to various tests. With DWA, this requirement can also be implemented in the data warehouse, as the models are fully integrated and a delivery chain can thus be set up across the various layers of the DWH. This can be run through automatically with specific deployment tools and previously defined tests can be carried out within this framework.
Documentation
Through the comprehensive integration of the various activities, DWA ensures automatic documentation of all processes and dependencies. This includes, in particular, a clear data lineage, i.e. the traceability of data through the different layers of the data warehouse or via different OLTP systems, as well as information about who made changes and when.










